Federated Learning (FL):

Khái niệm
Các mô hình ML/DL truyền thống thường yêu cầu dữ liệu gốc của người dùng được gửi lên một server trung tâm để train tập trung, điều này gây ảnh hưởng đến quyền riêng tư (privacy). Do đó, các mô hình hiện nay thường sử dụng FL để train mô hình một cách phân tán, dữ liệu được gửi lên là trọng số của mô hình thay vì dữ liệu gốc của người dùng cho nên vừa đảm bảo một phần privacy, vừa giảm thiểu được tài nguyên tính toán cho máy chủ trung tâm. Cụ thể, máy chủ trung tâm hay máy chủ tổng hợp (aggregation server) sẽ thực hiện khởi tạo mô hình và gửi cho các máy trạm để huấn luyện trên tập dataset của mình. Sau khi train xong, các máy này sẽ gửi trọng số mới về cho máy chủ tổng hợp để thực hiện tổng hợp mô hình cho round tiếp theo. Quá trình tổng hợp mô hình có thể sử dụng một số thuật toán phổ biến như FedAVG hoặc FedSGD, … Máy chủ trung tâm sẽ thực hiện lặp lại quá trình này đến khi nào đủ số round cần huấn luyện.
Vấn đề về đầu độc mô hình - giải pháp 1
Trong các mô hình FL, nếu có một số node cố tình gửi trọng số sai thì mô hình tổng hợp sẽ bị ảnh hưởng rất lớn. Vì vậy việc áp dụng một số cơ chế phát hiện là một điều bắt buộc. Thông thường, người ta sẽ sử dụng một số phương pháp để đo độ sai lệch giữa các bộ trọng số mà các máy trạm gửi lên với trọng số tổng hợp, ví dụ như Cosine Similarity. Cosine Similarity hoạt động bằng cách đo độ tương tự Cosine giữa trọng số của máy trạm i và server tổng hợp. Giá trị này được cho phép nếu nằm trong một ngưỡng nhất định, nếu ngoài ngưỡng này, trọng số của máy trạm i được xem là độc hại và sẽ không được dùng để tổng hợp ở máy chủ trung tâm.
Đảm bảo quyền riêng tư (privacy)
Mặc dù dữ liệu được gửi lên server trung tâm là trọng số huấn luyện thay vì dữ liệu gốc của người dùng nhưng chúng ta vẫn chưa thể đảm bảo hoàn toàn về privacy. Một số bài báo chỉ ra điều này là do: Từ trọng số của mô hình huấn luyện, người ta có thể suy ra một phần thông tin về dữ liệu gốc ban đầu. Vì vậy, để tăng khả năng đảm bảo privacy, có 2 cơ chế thường được sử dụng:
- Differential Privacy: Kỹ thuật này thực hiện thêm nhiễu vào trong dữ liệu / trọng số, nhằm làm khó khăn cho kẻ tấn công trong trường hợp muốn rút trích một phần thông tin gốc. Nhược điểm của kỹ thuật này là làm giảm độ chính xác của mô hình do nhiễu.
- Sử dụng kỹ thuật mật mã: Có thể kể đến như mã hóa đồng cấu (Homomorphic Encryption) cho phép tính toán trực tiếp trên dữ liệu bị mã hóa mà không cần thiết phải giải mã. Ví dụ: Ta có 2 thông điệp bản rõ là m1 và m2, hàm mã hóa Enc. Khi đó, Enc(m1) + Enc(m2) = m1 + m2 hoặc Enc(m1) * Enc(m2) = m1 * m2.
Blockchain:

Giới thiệu
Blockchain bắt đầu nổi lên từ sự kiện Bitcoin ra đời vào năm 2009, biến nó trở thành một công nghệ đầy hứa hẹn những năm gần đây với sự xuất hiện đa dạng của các nền tảng như Etherium, Polkadot, Cosmos, Near protocol, SUI, Aptos, … Về cơ bản, Blockchain là một cuốn sổ cái điện tử phi tâp trung, được lưu trữ minh bạch ở các node tham gia. Blockchain sử dụng các cơ chế đồng thuận để đảm bảo an toàn cho hệ thống, kiểm soát quá trình ghi dữ liệu vào sổ cái nhờ sự kết hợp với các kỹ thuật mật mã hiện đại. Ngoài ra, Blockchain còn có tính bất biến, nghĩa là tất cả dữ liệu trên blockchain sẽ không thể thay đổi. Cơ chế đồng thuận và kỹ thuật mật mã có thể xem là sương sống của hệ thống blockchain.Blockchain có thể chia làm hai loại chính là permissionless blockchain và permissioned blockchain. Permissionless là các blockchain cho phép mọi người đều có thể truy cập ví dụ như Bitcoin, Etherium. Trong khi Permissioned là các blockchain được kiểm soát bởi một nhóm người / tổ chức và chỉ cho phép những người được cấp phép truy cập. Ví dụ như Hyperledger Fabric.Giao thức đồng thuận cũng có thể chia làm hai loại là BFT-based (Byzantine Fault Tolerance-based) và PoX-based (Proof of X-based). Trước khi Bitcoin ra đời, các nền tảng blockchain thường dựa trên cơ chế BFT-based (ví dụ như Practical Byzantine Fault Tolerance), mặc dù các cơ chế này hoạt động với độ bảo mật cao nhưng thường khả năng scale out (mở rộng) thấp do số lượng message phải gửi trong mạng là quá lớn. Do đó, các cơ chế này thường dùng trong Permissioned blockchain. Sự ra đời của Bitcoin có thể xem là một bước tiến vượt bậc khi Blockchain này sử dụng cơ chế đồng thuận được đặt tên theo người / tổ chức sáng lập là Nakamoto (Nakamoto consensus). Các cơ chế sau này tương tự thì người ta thường dùng với cái tên Nakamoto-based consensus. Giao thức Nakamoto sử dụng cơ chế Proof of Work (PoW) để xác định người nào sẽ đảm nhận quá trình tạo khối. PoW là cơ chế giải đố, các thợ đào (miner) trong mạng cần phải giải một bài toán rất khó, người nào giải ra đầu tiên sẽ trở thành người đề xuất khối mới. Do những hạn chế của PoW (tốn tài nguyên, ảnh hưởng đến môi trường do phải giải quyết một bài toán rất khó), người ta đề xuất một cơ chế mới là Proof of Stake (PoS). PoS hoạt động bằng cách các node trong mạng stake tiền để trở thành các validator, người nào stake càng nhiều tiền thì khả năng trở thành validator càng lớn. Các validator này có nhiệm vụ xác thực các giao dịch, đảm bảo an toàn cho hệ thống, vì vậy nếu họ thực hiện các hành động sai trái thì sẽ bị phạt tiền và ngược lại thì sẽ nhận được tiền thưởng từ hệ thống. PoS được xem là ít an toàn hơn so với PoW nhưng thời gian sinh ra mỗi khối của PoS nhanh hơn PoW (10 phút) do đó TPS (transaction per second) của các blockchain dựa trên PoS thường cao hơn. Các cơ chế đồng thuận dựa trên PoX thường chạy nhanh hơn nhiều sơ với BFT-based nhưng lại không an toàn bằng vì các cơ chế này không đảm bảo đầy đủ tính chất Byzantine Fault Tolerance của một hệ thống phân tán mà chỉ đảm bảo một phần. Mặc dù vậy, do chi phí giao tiếp (communication cost) nhỏ, các giao thức đồng thuận này thường dễ dàng hơn trong việc áp dụng vào các permissionless blockchain. Hiện nay, các cơ chế đồng thuận dựa trên BFT không chỉ được dùng trong permissioned blockchain mà ngay cả permissionless blockchain cũng sử dụng (mặc dù chi phí lớn nên thường dùng kết hợp với PoS, PoW, … ), ví dụ như Zilliqa.
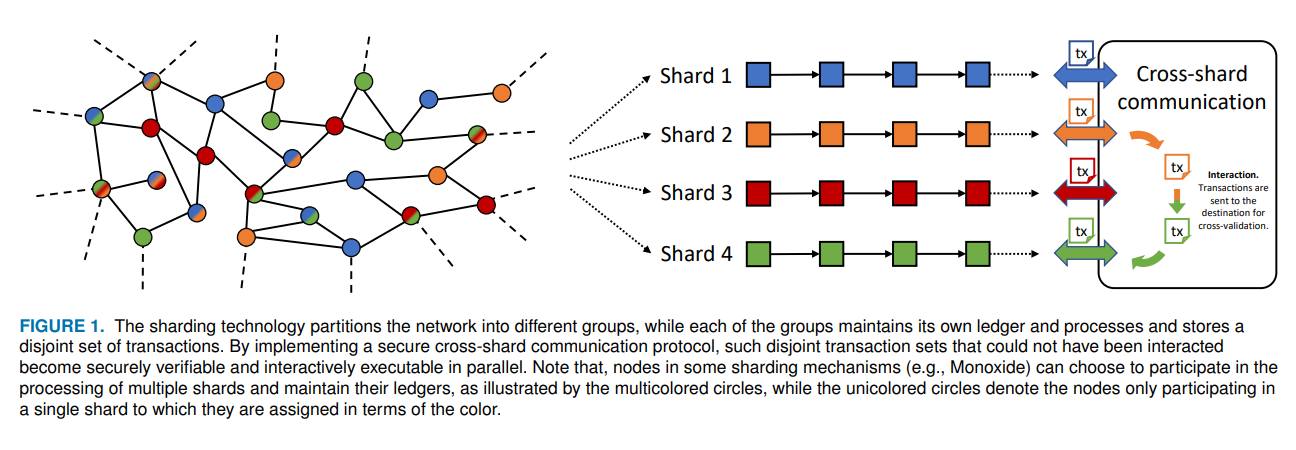
Kỹ thuật Sharding
(Vấn đề này mình có trình bày trong bài trước, mọi người có thể đọc lại để nắm bắt kiến thức một cách cụ thể nhất)Các cơ chế dựa trên PoX mặc dù đã cải thiện TPS rất nhiều so với trước đây nhưng vẫn rất hạn chế khi so sánh với Ripple (1500), Visa (24000). Do vậy, các hệ thống blockchain hiện đại cần phải có cơ chế scale out. Có nhiều hướng để thực hiện nhưng nổi bật trong những năm gần đây thì phải kể đến Sharding. Về cơ bản, Sharding là một kỹ thuật giúp cải thiện throughput của hệ thống blockchain bằng cách cố gắng thực thi các transaction một cách song song với nhau. Để đạt được yêu cầu này, hệ thống sẽ chia blockchain thành các phần mà chúng ta thường gọi là Shard. Mỗi phần như thế có thể xem như một blockchain riêng và có thể sử dụng các cơ chế đồng thuận khác nhau. Mặc dù cách này có thể giúp xử lý các transaction nhanh hơn nhưng nó cũng có nhược điểm về mặt bảo mật, đó là vì khi chia càng nhiều shard thì số lượng node cần để tấn công một shard càng nhỏ, mà chỉ cần kiểm soát một shard là có thể kiểm soát cả hệ thống. Một vấn đề nữa cần lưu ý đó là, mặc dù chia thành nhiều shard, với mỗi shard có thể xem như một blockchain khác nhau nhưng thực chất nó vẫn chỉ là một blockchain, tức là các shard này có sự liên hệ với nhau. Do đó khi xử lý cross-shard, cần phải có cơ chế verify rất cẩn thận, tránh double-spending.
Blockchain-enabled FL:

Kết hợp những ưu điểm của FL, Blockchain; những năm gần đây, người ta thường sử dụng mô hình kết hợp giữa chúng để hỗ trợ lẫn nhau trong việc xác thực, huấn luyện mô hình. Vấn đề đặt ra là giả sử máy chủ tổng hợp trong FL bị lỗi, nếu không có biện pháp xử lý thì sẽ tạo thành “nghẽn cổ chai” (bottleneck) trong quá trình training. Nhờ kết hợp với các giao thức đồng thuận trong blockchain, người ta có thể phát hiện và lựa chọn server tổng hợp khác trong trường hợp đó, giúp hệ thống kịp thời đáp ứng. Ngoài ra, nhờ vào tính chất minh bạch và bất biến của blockchain, dữ liệu được lưu lại phục vụ cho quá trình kiểm toán, truy vết sau này. Cụ thể, dữ liệu huấn luyện thường rất lớn nên người ta thường không lưu trực tiếp lên các hệ thống như Etherium hay Near, … vì chi phí lớn mà họ thường lưu dữ liệu đó lên các nên tảng như IPFS và lưu các giá trị hash của chúng lên các blockchain phục vụ mục đích xác thực (security). Như vậy sẽ đảm bảo tối ưu hơn cho hệ thống.
DRL-based sharding
Độ an toàn và throughput của các hệ thống kết hợp FL-blockchain sử dụng Sharding phụ thuộc rất nhiều vào các tham số như số lượng shard được chia, giao thức đồng thuận trong các shard, số lượng round cần huấn luyện, … do đó cần phải lựa chọn các tham số sao cho tối ưu. Tuy nhiên các sharding blockchain thường cố định các tham số này, gây khó khăn trong việc tối ưu hiệu suất hệ thống. Vì vậy một giải pháp sharding dựa trên DRL (Deep Reinforcement Learning) rất cần thiết để thiết lập các tham số sao cho thích nghi được với điều kiện hiện tại trong mạng.
Vấn đề về đầu độc mô hình - giải pháp 2
Để giảm thiểu các mô hình độc hại trọng FL, ngoài cách sử dụng Cosine Similarity ở trên, người ta cũng có thể sử dụng các mô hình kết hợp FL-Blockchain với quá trình chấm điểm các node tham gia huấn luyện, các node có điểm thấp dưới ngưỡng nào đó sẽ bị xem là độc hại và bị loại khỏi quá trình training (có kết hợp sharding). Cụ thể như sau: Mỗi shard sẽ có một leader thực hiện tổng hợp trọng số, leader này sẽ chấm điểm các node trong shard đó dựa theo thời gian phản hồi trọng số huấn luyện. Nếu phản hồi trong thời gian cho phép sẽ được cộng điểm, không phản hồi hoặc quá thời gian sẽ bị trừ điểm. Ngoài ra, lịch sử phản hồi cũng được đánh trọng số để chấm điểm, các phản hồi trong quá khứ sẽ có trọng số nhỏ hơn phản hồi gần đây (ít quan trọng hơn). Hơn nữa, cũng cần có cơ chế để các shard có thể chấm điểm chéo cho nhau, hoặc các leader có thể chia sẻ thông tin điểm ở shard của mình để đồng bộ điểm cho cả hệ thống.
Tham khảo: Y. Lin et al., "DRL-Based Adaptive Sharding for Blockchain-Based Federated Learning," in IEEE Transactions on Communications, vol. 71, no. 10, pp. 5992-6004, Oct. 2023, doi: 10.1109/TCOMM.2023.3288591.
(Võ Trường Trung Hiếu)