Phương pháp để các hệ thống hoặc mạng có thể tránh bị malware hoặc lưu lượng mạng xấu từ Internet tấn công là triển khai các hệ thống ở các vị trí nhằm bảo vệ các thông tin quan trọng trong các máy tính hoặc hệ thống mạng. Những hệ thống phát hiện các lưu lượng mạng độc hại như vậy được gọi là các hệ thống phát hiện xâm nhập (IDS) và được huấn luyện với các dữ liệu lưu lượng mạng Internet. Tập dữ liệu phổ biến nhất là NSL-KDD, cũng là bộ dữ liệu chuẩn cho dữ liệu Internet hiện nay.
Khi làm nghiên cứu về lĩnh vực bảo mật thì cái tên DARPA ắt hẳn không phải là cái tên xa lạ với mọi người. DARPA là một bộ dữ liệu thô cơ sở. Trong khi đó, KDD99 là phiên bản trích xuất tính năng của bộ dữ liệu DARPA. Tiếp đó, NSL-KDD là phiên bản được loại bỏ và giảm kích thước của bộ dữ liệu KDD99.

NSL-KDD khôngphải là tập dữ liệu đầu tiên dành cho các IDS. Đã từng có một cuộc thi là KDDCup, một cuộc thi quốc tế về các công cụ Khai thác tri thức và khai phá dữ liệu.Năm 1999, cuộc thi này được tổ chức với mục đích thu thập các bản ghi lưu lượngmạng. Nhiệm vụ của cuộc thi là xây dựng một hệ thống phát hiện xâm nhập mạng, mộtmô hình dự đoán có thể phân biệt được các kết nối “xấu” – gọi là xâm nhập hoặctấn công – và các kết nối thông thường. Kết quả sau cuộc thi đã thu thập được mộtlượng bản ghi lưu lượng mạng và gom thành tập dữ liệu gọi là KDD’99, và từ đó,tập dữ liệu NSL-KDD được tạo ra, như là một phiên bản đã sửa đổi, tối ưu hóa củaKDD’99 từ Đại học New Brunswick.
Tập dữ liệu nàygồm 4 tập dữ liệu con: KDDTest+, KDDTest-21, KDDTrain+, KDDTrain+_20Percent, mặcdù KDDTest-21 và KDDTrain+_20Percent là các tập con của KDDTest+ và KDDTrain+.Từ đây, KDDTrain+ sẽ được xem là tập huấn luyện và KDDTest+ sẽ được xem là tậpkiểm tra. Tập KDDTest-21 là một tập con của tập kiểm tra, loại bỏ những bản ghidữ liệu khó nhất (điểm 21) và tập KDDTrain+_20Percent là tập con của tập huấnluyện, với số bản ghi bằng 20% tổng số bản ghi có trong tập huấn luyện. Nóicách khác, các bản ghi lưu lượng mạng có trong KDDTest-21 vàKDDTrain+_20Percent đã lần lượt có trong các tập kiểm tra và tập huấn luyện, đồngthời không có bản ghi nào đồng thời tồn tại trong cả 2 tập dữ liệu.
Tập dữ liệu gồm các bản ghi lưu lượng mạng Internet được quan sát bởi một mạng phát hiện xâm nhập đơn giản và là những lưu lượng một IDS có thể gặp phải, là những dấu vết còn sót lại. Tập dữ liệu gồm 43 thuộc tính trong mỗi bản ghi, với 41 thuộc tính liên quan đến chính lưu lượng, 2 thuộc tính cuối là nhãn (tấn công hoặc không tấn công) và điểm (mức độ nghiêm trọng của lưu lượng đầu vào).
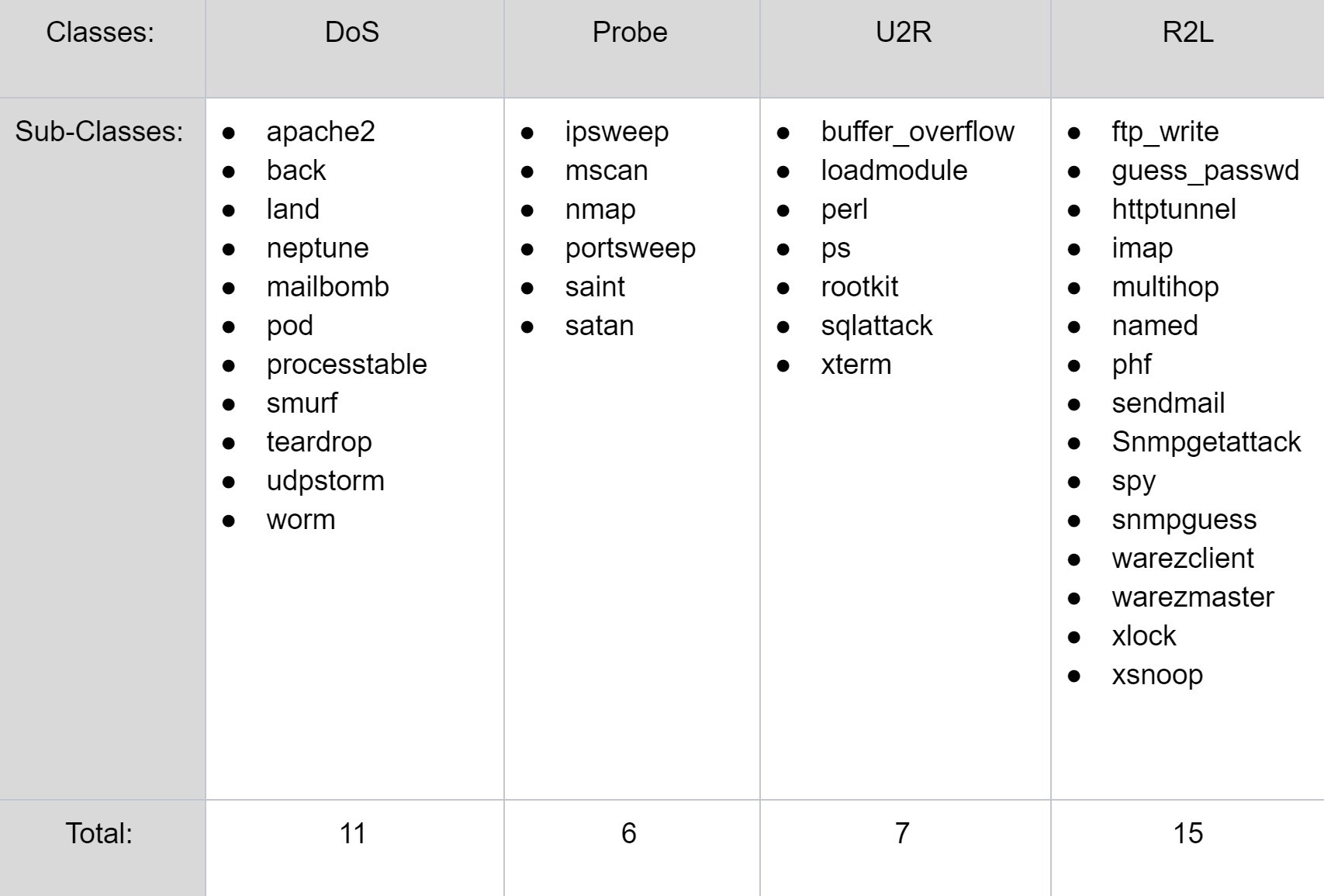
Trong tập dữ liệu NSL-KDD có 4 lớp tấn công bao gồm: Tấn công từ chối dịch vụ (Denial of Services – DoS), Do thám (Probe), User to Root (U2R) và Remote to Local (R2L).
Mô tả ngắn gọn của mỗi lớp tấn công như sau:
- DoS là kiểu tấn cônghướng đến việc gián đoạn lưu lượng mạng được gửi đến hoặc đi từ hệ thống mụctiêu. IDS bị tấn công với một lượng lưu lượng không bình thường mà nó không thểxử lý được và tự ngưng hoạt động để bảo vệ chính nó. Điều này làm cho lưu lượngbình thường không đi đến được mạng. Cho ví dụ, một đơn vị bán hàng trực tuyến bịtràn ngập các đơn hàng online trong một ngày có khuyến mãi lớn, và do mạngkhông thể xử lý tất cả các yêu cầu nên nó sẽ ngưng hoạt động, khiến cho cáckhách hàng không thể thực hiện các giao dịch thanh toán hàng. Đây là tấn côngphổ biến nhất trong tập dữ liệu.
- Do thám (Probe) là kiểutấn công cố gắng thu thập các thông tin từ một mạng nào đó. Mục tiêu giống nhưmột kẻ trộm đánh cánh các thông tin quan trọng, bất kể là thông tin cá nhân củangười dùng hoặc thông tin tài khoản ngân hàng.
- U2R là kiểu tấn công bắtđầu từ một tài khoản người dùng thông thường và cố gắng chiếm quyền truy cậpvào hệ thống hoặc mạng như người dùng root. Kẻ tấn công cố tấn công vào các điểmyếu trong hệ thống để chiếm quyền root.
- R2L là kiểu tấn công cốgắng chiếm quyền truy cập vào hệ thống từ một máy tính từ xa. Một kẻ tán congkhông có quền truy cập nội bộ vào hệ thống hoặc mạng và cố gắng tấn công để tìmcách truy cập vào mạng.
Cần lưu ý rằngtừ những mô tả phía trên, DoS hoạt động khác so với 3 nhóm tấn công còn lại, ởđó DoS cố gắng làm hệ thống ngưng hoạt động để cuối cùng ngăn các lưu lượngbình thường, trong khi các tấn công khác chỉ âm thầm xâm nhập hệ thống và cố gắngkhông bị phát hiện.
Bảng bên dưới (Hình 2) liệt kê các lớp con của mỗi nhóm tấn công ở trên trong bộ dữ liệu:
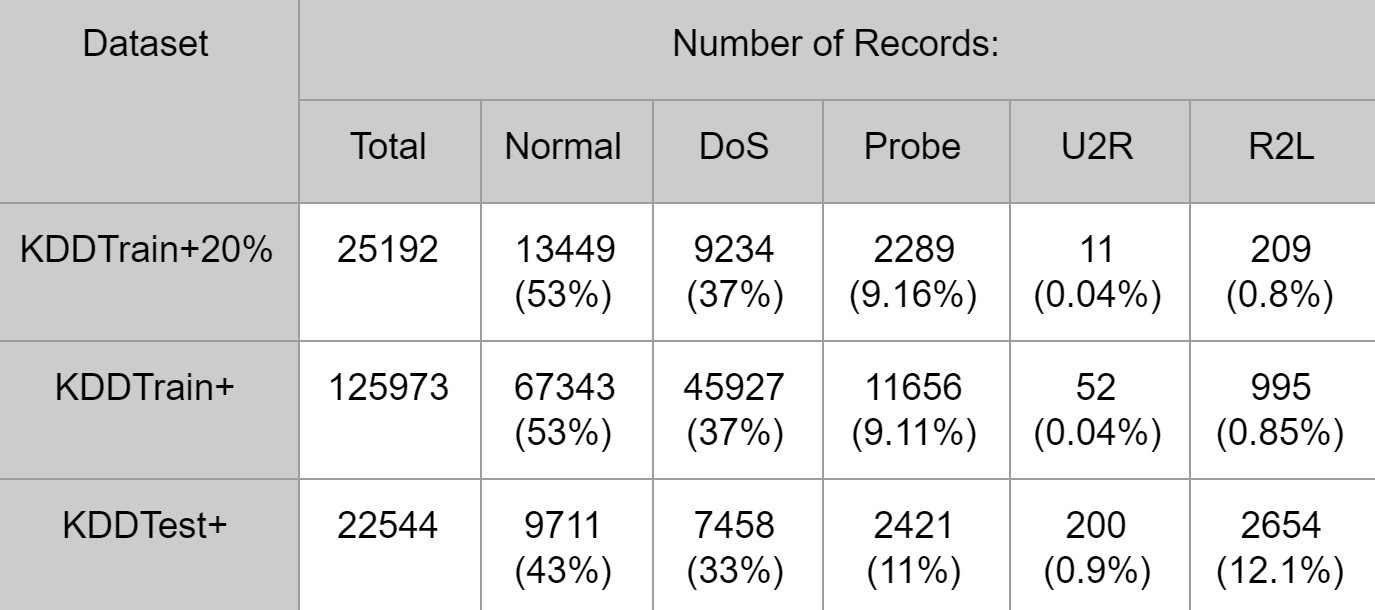
Dù cùng tồn tại trong tập dữ liệu nhưng độ phân bố của các tấn công này cũng không đồng đều, như ta có thể thấy trong bảng bên dưới (Hình 3). Về cơ bản, hơn một nửa các bản ghi trong tập dữ liệu là lưu lượng bình thường, và số lượng bản ghi của tấn công U2R và R2L khá thấp. Mặc dù thấp, tập dữ liệu vẫn đại diện chính xác cho phân bổ của các lưu lượng tấn công trên mạng Internet ngày nay, khi hầu hết các tấn công là DoS và tấn công U2R và R2L thường ít thấy.
Các thuộc tính trong mỗi bản ghi lưu lượng cung cấp các thông tin về tấn công có thể chia làm 4 loại: Cơ bản (Intrinsic), Nội dung (content), host-based và time-based, cụ thể:
- Các thuộc tính cơ bản có thể lấy được từ header của cacsgois tin mà không cần phân tích payload của nó, và chứa các thông tin cơ bản về gói tin, bao gồm các thuộc tính từ 1-9.
- Các thuộc tính nội dung chứa các thông tin về các gói tin gốc, khi chúng được gửi trên mạng dưới dạng nhiều phân mảnh. Với thông tin này, hệ thống có truy cập vào payload của nó. Loại này gồm các thuộc tính từ 10-22.
- Các thuộc tính time-based (liên quan đến thời gian) phân tích lưu lượng đầu vào theo các cửa sổ có độ dài 2 giây và chứa các thông tin như có bao nhiêu kết nối đã được tạo ra đến cùng một host. Những thuộc tính này hầu hết là các biến đếm hoặc tốc độ hơn là các thông tin về nội dung của lưu lượng. Loại này gồm các thuộc tính từ 23-31.
- Các thuộc tính host-based (liên quan đến host) tương tự như các thuộc tính time-based, chỉ khác ở chỗ thay vì phân tích với các cửa sổ 2 giây, nó phân tích một chuỗi các kết nối được tạo ra (bao nhiêu yêu cầu được gửi đến cùng một host trong x kết nối). Những thuộc tính này được thiết kế dành cho các tấn công truy cập, vốn thường dài dơn cửa sổ thời gian 2 giây. Loại này gồm các thuộc tính 32-41.
Kiểu dữ liệu của các thuộc tính có thể chia làm 4 loại:
- 4 thuộc tính kiểu phân loại (2, 3, 4, 42)
- 6 thuộc tính kiểu nhị phân (7, 12, 14, 20, 21, 22)
- 23 thuộc tính rời rạc (8, 9, 15, 23-41, 43)
- 10 thuộc tính kiểu liên tục (1, 5, 6, 10, 11, 13, 16, 17, 18, 19)
Danh sách các giá trị có thể có của các thuộc tính kiểu phân loại có thể xem ở bảng dưới (Hình 4). Trong đó, có 3 giá trị cho thuộc tính Protocol Type, 60 giá trị cho thuộc tính Service và 11 giá trị Flags.

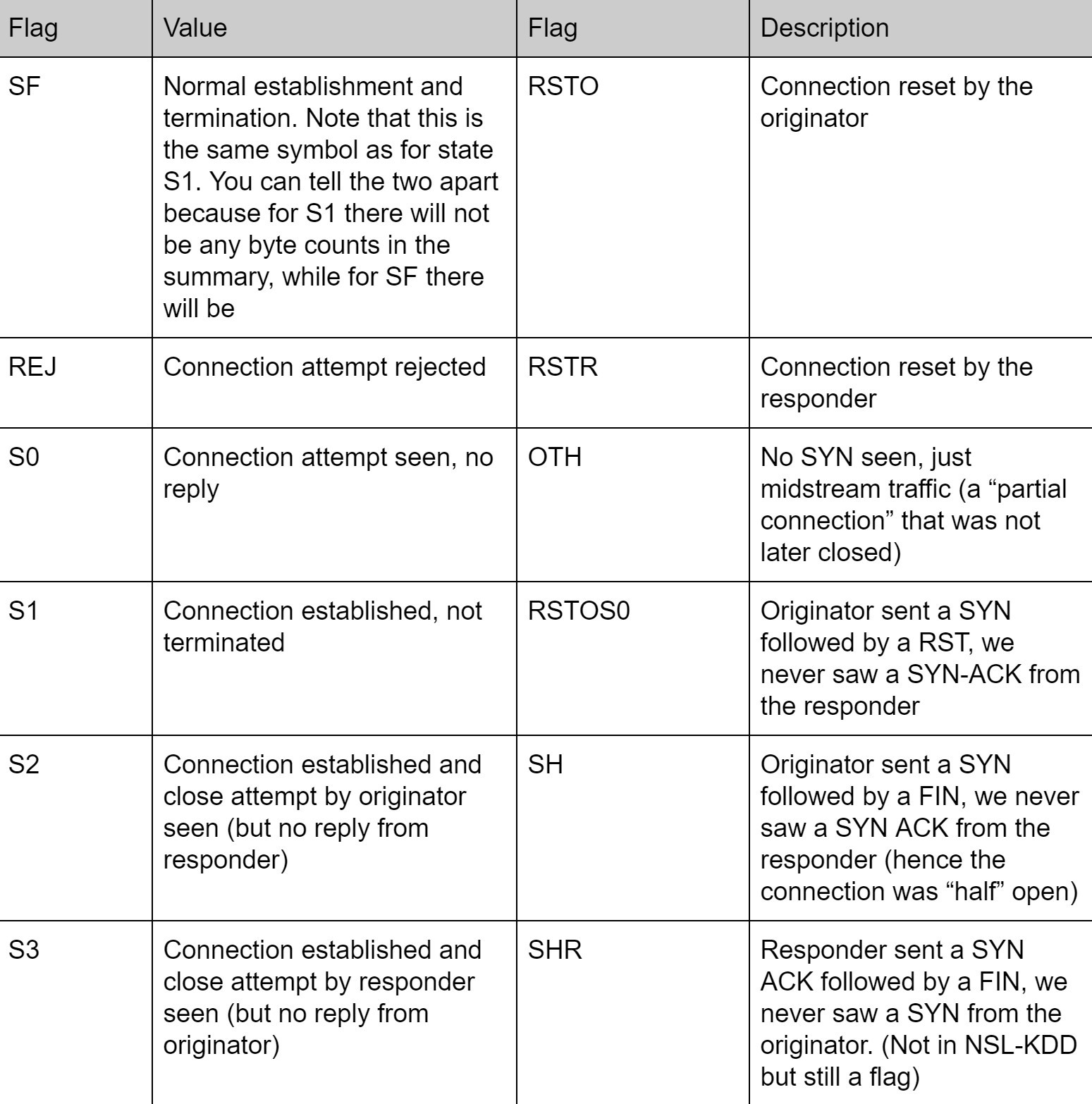
Không giống như các thuộc tính Protocol Type hoặc Service có giá trị tự giải thích cho ý nghĩa của nó (giá trị mô tả kết nối), thuộc tính Flags hơi khó hiểu. Flag mô tả trạng thái của kết nối và các cờ trong gói tin có được bật hay không. Mỗi giá trị của Flag đại diện cho một trạng thái của kết nối và ý nghĩa của mỗi giá trị có thể xem ở bảng bên dưới (Hình 5).
Cuối cùng, để kết thúc bài viết này, phần mô tả chi tiết về từng thuộc tính trong bộ dữ liệu NSL-KDD được diễn giải cụ thể ở liên kết Google Sheet.
Tham khảo và lược dịch bài viết của Gerry Saporito