Trí tuệ nhân tạo hoàn toàn có thể bị đánh lừa
Mạng nơ-ron hay mạng thần kinh nhân tạo đang được tung hô do đạt được hiệu suất siêu phàm trong nhiều lĩnh vực, nhưng chúng rất dễ bị đánh lừa.
Bạn có thể tham khảo một demo về sự "thiếu hiểu biết, cả tin" của mạng thần kinh nhân tạo này trong nền tảng web adversarial.js mới được công bố bởi kennysong như hình chụp bên dưới (Hình 1-2).
Thử ngay demo tại liên kết sau: https://github.com/kennysong/adversarial.js
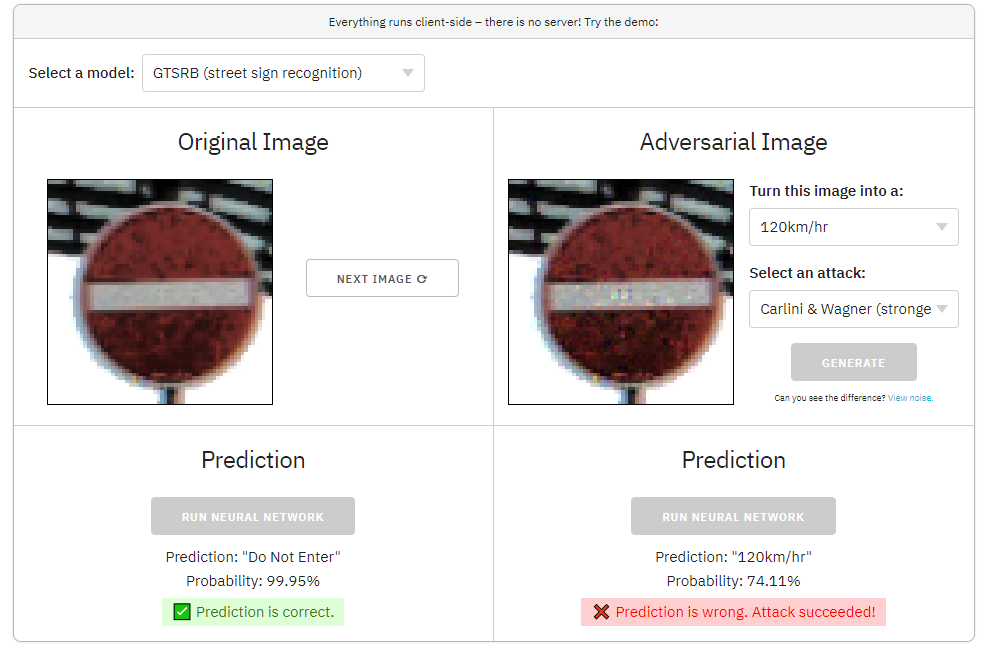
Hình 1 - Mạng nơ-ron bị đánh lừa khi dự đoán Biển báo "Stop" thành Biển báo "120km/h"
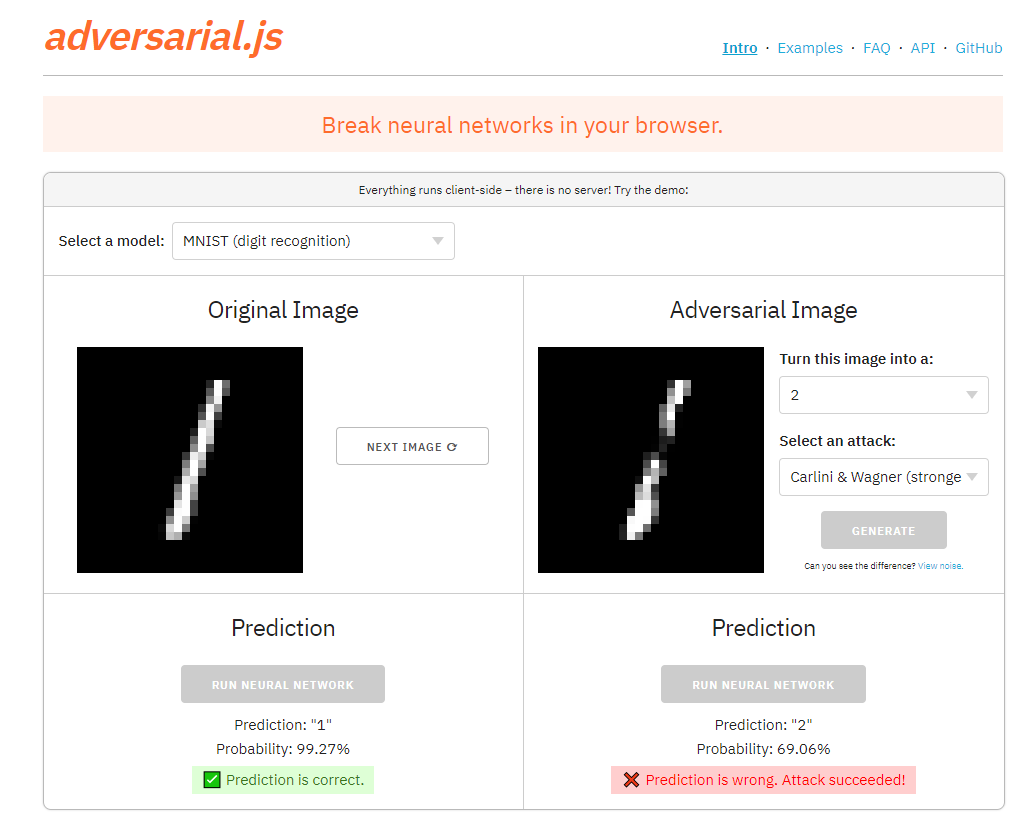
Hình 2- Mạng nơ-ron bị đánh lừa khi dự đoán số 1 thành số 2
Trong bản demo ở trên, chúng ta có thể buộc mạng nơ-ron dự đoán bất cứ điều gì chúng ta muốn. Bằng cách thêm nhiễu (noise) gần như vô hình vào một bức ảnh, chúng tôi khiến mạng nơ-ron bị sai lệch khi cho kết quả dự đoán số "1" thành "2", dự đoán biển báo "Stop" thành biển báo "120 km/giờ" và hình ảnh một chú chó được dự đoán thành hình ảnh một xúc xích.
Những hình ảnh nhiễu này được gọi là các mẫu đối nghịch (adversarial exaple). Chúng phá vỡ tính toàn vẹn của các hệ thống học máy và ảo tưởng về hiệu suất siêu phàm của các hệ thống dựa trên trí tuệ nhân tạo đang được tung hô ngoài thực tế.
Vì sao đây là vấn đề nghiêm trọng?
Thế giới của chúng ta đang ngày càng trở nên tự động hóa, nhưng những hệ thống này lại mắc phải lỗi kỳ lạ khi gặp dữ liệu đối nghịch (hay còn gọi là tấn công đối kháng). Nếu hệ thống học máy không được bảo vệ đúng cách, những kẻ tấn công có thể:
- Mạo danh người khác trong hệ thống nhận dạng khuôn mặt
- Buộc các phương tiện tự lái nhận dạng sai biển báo và chướng ngại vật trên đường phố
- Bỏ qua kiểm duyệt nội dung và bộ lọc thư rác trong mạng xã hội
- Đưa các byte đối nghịch vào phần mềm độc hại (mã độc) để vượt qua hệ thống chống vi-rút, sâu máy tính, trojan,...
- Vượt mặt tường lửa, các hệ thống phát hiện xâm nhập (IDS) bằng các mẫu tấn công đối kháng chứa nhiễu
- Thay đổi trên các tấm séc điện tử trong ứng dụng ngân hàng di động
(và còn rất nhiều trường hợp nguy hiểm hơn nữa)
Sự cố này có bị giới hạn trong lĩnh vực phân loại hình ảnh với mạng thần kinh nhân tạo không?
Câu trả lời là Không. Các mẫu đối nghịch (adversarial example) tồn tại trong hầu hết mọi tác vụ học máy: nhận dạng giọng nói, phân loại văn bản, phát hiện gian lận, dịch máy (machine translation), học tăng cường (reinforcement learning), ....
Hơn nữa, tất cả các mô hình học máy (không chỉ mạng nơ-ron) đều dễ bị tấn công. Trên thực tế, các mô hình đơn giản hơn như hồi quy logistic (logistic regression) thậm chí còn dễ bị tấn công hơn.
Cuối cùng - ngoài các mẫu đối nghịch - còn có nhiều vectơ tấn công đối nghịch khác, bao gồm nhiễm độc dữ liệu (data poisoning), mô hình hóa ngược (model backdooring), trích xuất dữ liệu (data extraction) và đánh cắp mô hình (model stealing).
Làm cách nào để chống lại các mẫu đối nghịch?
Có một số biện pháp phòng thủ được đề xuất để phòng tránh khả năng bị đánh lừa đối trước các tấn công đối kháng, bao gồm huấn luyện đối nghịch (adversarial training) và kiểm soát đầu vào (admission control). Tuy nhiên, không có biện pháp phòng thủ nào là phổ biến và nhiều biện pháp đã được chứng minh là không hiệu quả, vì vậy hãy xác định rủi ro cẩn thận và xem xét sử dụng một phương pháp phòng thủ một cách thích hợp cho hệ thống học máy của mình.
Tóm lại, hãy thử hình dung, điều gì xảy ra nếu ai đó có thể khiến hệ thống của bạn dự đoán bất cứ điều gì họ muốn? Rõ ràng, đó là một sự cố nghiêm trọng.
Một số nguồn tài liệu để học và nghiên cứu về tấn công đối kháng
- The full FAQ
- The directory of attacks (try running locally and playing with various settings)
- [Blog] CleverHans – start here
- [Blog] Gradient Science – start here
- [Tutorial] Adversarial Robustness - Theory and Practice
- [Paper] SoK: Towards the Science of Security and Privacy in Machine Learning
- [Paper] Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning