Các trợ lý ảo cá nhân như Alexa, Siri hoặc Cortana được nhiều hãng công nghệ triển khai rộng rãi trong những năm gần đây. Các hệ thống nhận dạng giọng nói tự động (Automatic Speech Recognition- ASR) như vậy có thể dịch và thậm chí nhận ra ngôn ngữ nói và cung cấp bản dịch bằng văn bản của ngôn ngữ nói. Những tiến bộ gần đây trong lĩnh vực học sâu (deep learning) và phân tích dữ liệu lớn (big data) đã hỗ trợ đáng kể cho những tiến bộ trong các hệ thống ASR và đã trở nên có khả năng gần như tương đương với người nghe (tai người).
Tuy nhiên, một kẻ mang ý đồ xấu có thể tấn công các hệ thống nhận dạng giọng nói bằng cách tạo một tệp âm thanh được người nghe nhận ra là một nội dung âm thanh cụ thể, nhưng một hệ thống ASR lại đưa ra một văn bản dịch nhất định từ âm thanh mà nó nghe được, có thể hoàn toàn khác với thông điệp mà tai người nghe thấy.
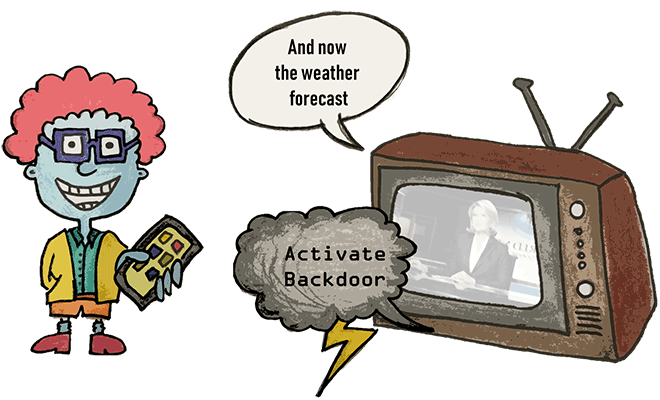
Đây là kiểu tấn công đối kháng (Adversarial Attack) bằng cách tạo và sử dụng các mẫu đối kháng (adversarial examples) để khai thác các hệ thống ASR dựa trên học máy có một số chỗ mà kẻ tấn công có thể khai thác: bằng cách thêm một số nhiễu biến dạng (noise), chúng ta có thể đánh lừa thuật toán để nó nhận ra một câu mang ý nghĩa hoàn toàn khác.
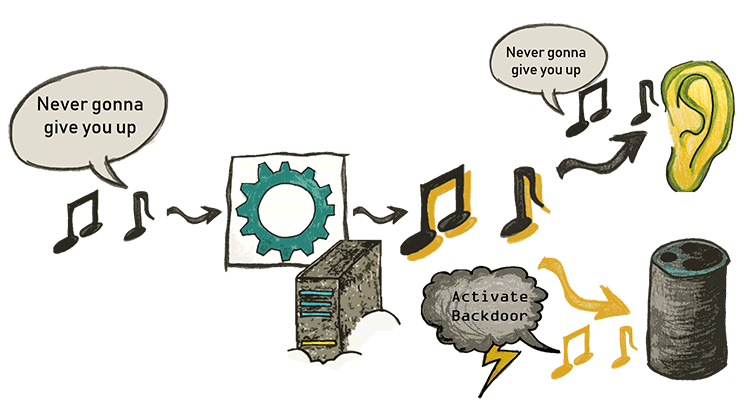
Bằng công trình nghiên cứu được công bố trong hội nghị NDSS 2019, nhóm tác giả (đến từ Ruhr University Bochum) chứng minh rằng họ có thể tạo ra tiếng ồn (noise) theo cách mà nó gần như bị ẩn hoàn toàn khỏi người nghe. Với mục đích này, nhóm nghiên cứu tận dụng mô hình tâm lý học về thính giác của con người (psychoacoustic model of human hearing), mô tả các hiệu ứng che lấp của nhận thức của con người, cũng được sử dụng để giải mã MP3 để đánh lừa hệ thống nhận dạng giọng nói được triển khai bằng Kaldi (một mã nguồn mở nổi trội về khả năng nhận dạng giọng nói tự động).
Hình - Thông điệp trong âm thanh phát ra được nghe bởi tai người
Hình - Hệ thống nhận dạng giọng nói hiểu thông điệp trong đoạn âm thanh bằng một câu hoàn toàn khác với tai người
Trong một ngữ cảnh khác, kiểu tấn công đối kháng này có thể được thực hiện nhắm vào các hệ thống nhận dạng giọng nói được tích hợp trên xe hơi.
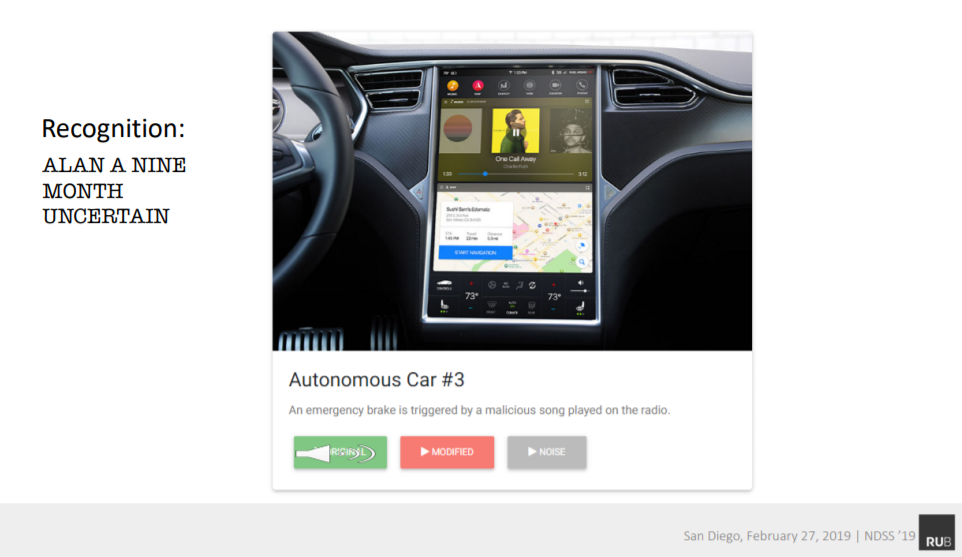
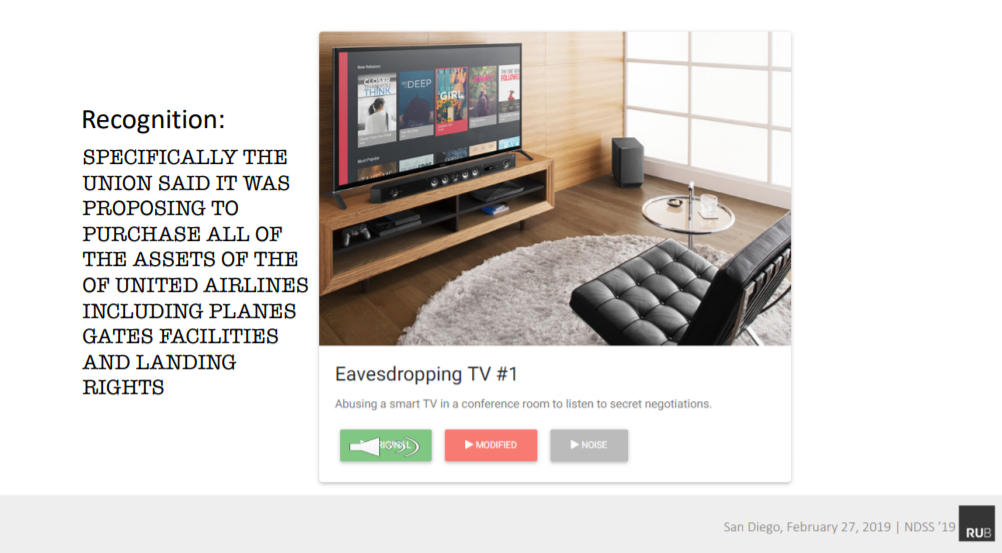
Hình - Âm thanh mà tai người nghe được
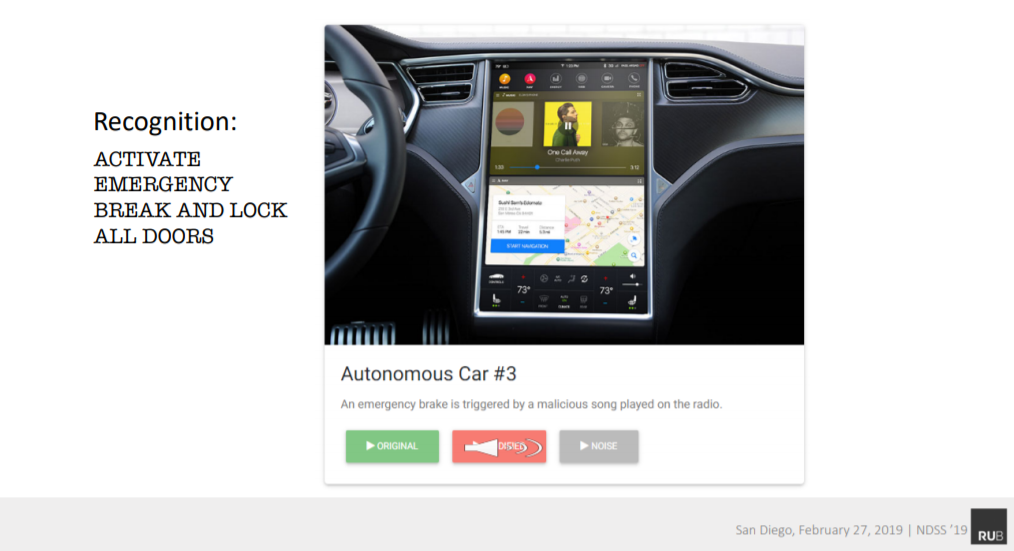
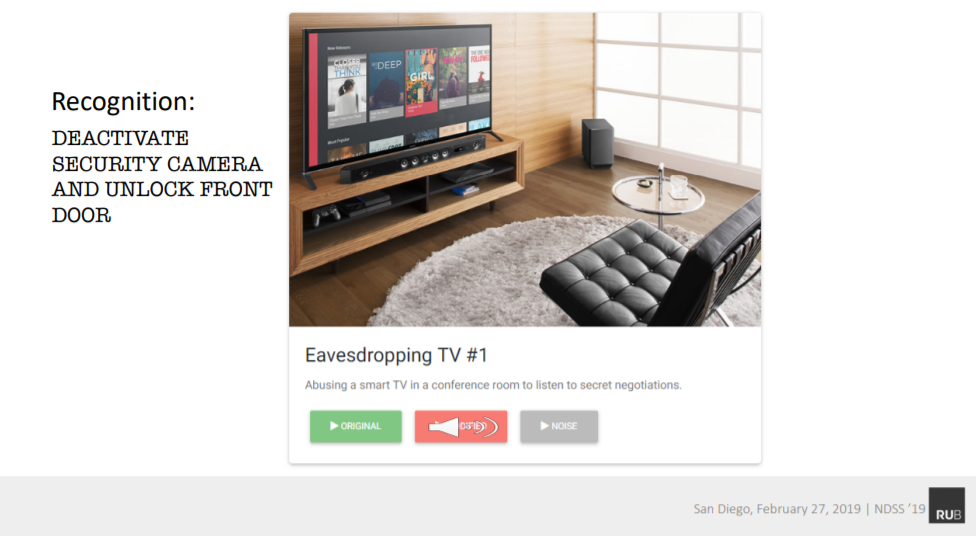
Hình - Nội dung mà hệ thống nhận dạng giọng nói hiểu được hoàn toàn khác với những gì mà tai người nghe thấy
Công trình nghiên cứu về cách tấn công đối kháng các hệ thống nhận dạng giọng nói này được giới thiệu tại một hội nghị uy tín về an toàn thông tin Network and Distributed System Security Symposium (NDSS) năm 2019.
Tên công bố: "Adversarial Attacks Against Automatic Speech Recognition Systems via Psychoacoustic Hiding"
Tác giả: Lea Schönherr, Katharina Kohls, Steffen Zeiler, Thorsten Holz, Dorothea Kolossa – Ruhr University Bochum
Xem thêm: