STAMINA là một dự án hợp tác giữa Microsoft và Intel Labs để giải quyết bài toán phát hiện và phân loại mã độc dựa trên cách tiếp cận học sâu (deep learning).
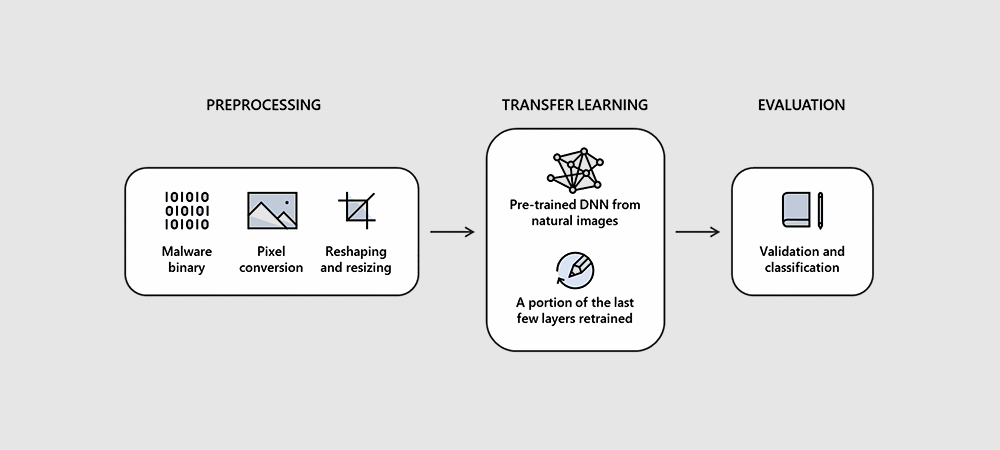
Hình 1 - Qui trình thực hiện trong dự án nghiên cứu STAMINA
Đây là một dự án hợp tác mới giữa 2 bên nhằm nghiên cứu khả năng áp dụng một cách tiếp cận dựa trên các tiến bộ của trí tuệ nhân tạo trong lĩnh vực xử lý hình ảnh để phân loại và xác định mã độc. Cụ thể, STAMINA (STAtic Malware-as-Image Network Analysis) dựa trên một kỹ thuật chuyển đổi các mẫu mã độc thành các mẫu ảnh xám (grayscale), sau đó thực hiện quét qua hình ảnh để tìm các mẫu cấu trúc hay văn bản (text) nhằm chỉ ra hình ảnh đó có phải là tương ứng với một mẫu mã độc hay không.
STAMINA hoạt động như thế nào?
Đội ngũ nghiên cứu của Intel và Microsoft nói rằng toàn bộ qui trình được thực hiện qua vài bước đơn giản. Đầu tiên, dữ liệu đầu vào là một tập tin nhị phân được chuyển đổi sang dạng chuỗi (stream) các dữ liệu pixel thô (raw pixel). Các nghiên cứu viên sẽ lấy chuỗi pixel 1 chiều này (1-D) chuyển thành hình ảnh 2 chiều (2D) , để chocasc thuật toán phân tích hình ảnh thông thường có thể hoạt động được.
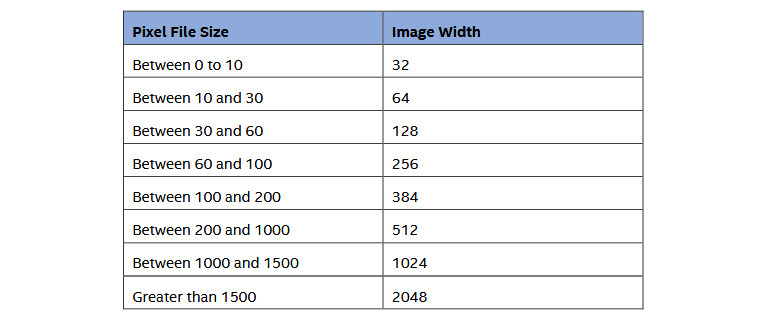
Kích thước của ảnh được chọn dựa trên kích thước của tập tin dữ liệu đầu vào, như thống kê bảng dưới đây.
Sau khi tổng hợp chuỗi các pixel thô thành hình ảnh 2D, các nhà nghiên cứu tiến hành điều chỉnh kích thước (resize) của hình ảnh xuống dạng nhỏ hơn. Nhóm nghiên cứu của Intel & Microsoft nói rằng quá trình thay đổi kích thước ảnh không làm "ảnh hưởng tiêu cực đến kết quả phân loại", và đây là một bước cần thiết để đảm bảo tài nguyên tính toán trong trường hợp ảnh có kích thước quá lớn với hàng tỉ pixel. Điều này nếu không được xử lý, sẽ làm kéo giảm khả năng phân tích của hệ thống đi xuống.
Bức ảnh sau khi được điều chỉnh kích thước sẽ được đưa qua mạng nơ-ron sâu tiền huấn luyện (pre-trained deep neural network (DNN)) để quét ảnh 2D này và gán nhãn nó là sạch hay nhiễm mã độc. Microsoft nói rằng dự án này được cung cấp 2.2 triệu mẫu tập tin thực thi bị nhiễm (infected PE (Portable Executable)) làm cơ sở cho việc nghiên cứu.
Cụ thể, các nghiên cứu viên sử dụng 60% các mẫu mã độc đã biết (đã gán nhãn) để huấn luyện cho thuật toán DNN, 20% mẫu dùng cho việc kiểm tra (validate) DNN, và 20% còn lại được sử dụng cho quá trình kiểm thử thật sự (testing). Kết quả được đội ngũ nghiên cứu đưa ra với độ chính xác khá cao (99.07%) trong việc nhận dạng và phân loại mã độc từ file thực thi PE. Tỉ lệ dương tính giả (false positive - cảnh báo sai) chỉ 2.58%.
"Những kết quả này thật sự khuyến khích việc sử dụng các mô hình học sâu cho mục đích phân loại mã độc", Jugal Parikh & Marc Marino , 2 nhà nghiên cứu của Microsoft đại diện cho Microsoft Threat Protection Intelligence Team. tham gia vào dự án này đưa ra nhận xét.
Microsoft đầu tư cho máy học
Nghiên cứu này là một phần trong những nỗ lực gần đây của Microsoft trong việc cải thiện phát hiện phần mềm độc hại bằng các kỹ thuật học máy.
STAMINA đã sử dụng một kỹ thuật gọi là học sâu (Deep learning). Deep learning là một tập hợp con của machine learning (ML), một nhánh của trí tuệ nhân tạo (AI), dùng để chỉ các mạng máy tính thông minh có khả năng tự học từ dữ liệu đầu vào được lưu trữ ở định dạng không có cấu trúc hoặc không được gắn nhãn - trong trường hợp này, một tập tin nhị phân ngẫu nhiên của phần mềm độc hại .
Microsoft cho biết, mặc dù STAMINA là chính xác và nhanh chóng khi làm việc với các tệp nhỏ hơn, nhưng nó lại gặp nhiều hạn chế khi hoạt động trên các tệp lớn hơn.
"Đối với các ứng dụng kích thước lớn hơn, STAMINA trở nên kém hiệu quả hơn do những hạn chế trong việc chuyển đổi hàng tỷ pixel thành hình ảnh JPEG và sau đó thay đổi kích thước chúng", Microsoft cho biết trong một bài đăng trên blog vào tuần trước.
Tuy nhiên, điều này rất có thể không thành vấn đề, vì dự án chỉ có thể được sử dụng cho các tệp nhỏ, với kết quả tuyệt vời.
Trong một cuộc phỏng vấn với ZDNet hồi đầu tháng này, Tanmay Ganacharya, Giám đốc Nghiên cứu Bảo mật của Microsoft Threat Protection, cho biết Microsoft hiện phụ thuộc rất nhiều vào việc học máy để phát hiện các mối đe dọa mới và hệ thống này sử dụng một mô-đun học máy khác đang được triển khai cho hệ thống khách hàng hoặc máy chủ Microsoft.
Microsoft hiện sử dụng các công cụ mô hình học máy (machine learning - ML) phía máy khách (client-side), các công cụ mô hình học máy phía đám mây (cloud-side), các mô-đun học máy để nắm bắt (capture) các chuỗi hành vi hoặc nắm bắt, ghi nhận lại nội dung của tệp, Ganacharya nói.
Dựa trên các kết quả được báo cáo, STAMINA có thể là một trong những mô-đun ML mà chúng ta có thể sớm thấy được triển khai tại Microsoft như một cách để phát hiện phần mềm độc hại.
Hiện tại, Microsoft có thể làm cho phương pháp này hoạt động tốt hơn các công ty khác chủ yếu nhờ vào dữ liệu tuyệt đối mà họ sở hữu từ hàng trăm triệu lượt cài đặt Windows Defender.
"Bất kỳ ai cũng có thể xây dựng một mô hình, nhưng dữ liệu được dán nhãn, số lượng và chất lượng của nó, thực sự giúp đào tạo các mô hình học máy một cách thích hợp, tối ưu và từ đó xác định mức độ hiệu quả của chúng", Ganacharya nói.
"Và chúng tôi, tại Microsoft, có lợi thế vì chúng tôi có các cảm biến (sensor) mang lại cho chúng tôi nhiều tín hiệu thú vị thông qua email, qua danh tính, qua điểm cuối (endpoint) và có thể kết hợp chúng lại với nhau."
Tham khảo và chuyển ngữ từ bài viết của Catalin Cimpanu trên Zdnet